
The Rise Of Physical AI
Published:
After spending time working with multispectral computer vision payloads and embedded systems, it became apparent how different it is to process data on a screen versus the physical, real-world interaction. For the past decade, Artifical Intelligence has been strictly “disemmbodied”, where it lives inside servers in Data Centes, processing text and generating pixels on a screen. However, the next frontier of machine learning isn’t just about thinking, it’s about acting especially in the real, physical world.
We are currently witnessing the transition from Generative AI to Physical AI. In this post, I’ll break down what Physical AI actually is and how we’re bridging the gap between digital intelligence and physical actuation.
Background
What is Physical AI?
Traditionally, an artificial intelligence’s output is just a classification label or a string of characters in a text or a generated image. On the other hand, Physical AI outputs movement and force. Physical AI lets autonomous systems like robots, camera and self-driving vehicles perceive, understand, reason, perform and orchestrate complex actions in the real physical world autonomously.
We tend to assume that just because an Large Language Model (LLM) can write a complex Python script or pass a high level exam such as the bar, it possess this so called “Artificial General Intelligence” (which is a hypothetical type of AI that can match or surpass all human capabilites on a variety of cognitive benchmarks).
Core Ideas
VLA (Vision-Language-Action) Models
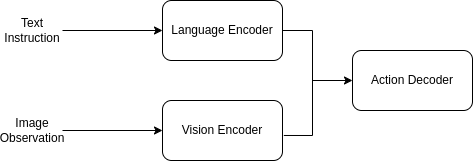
The current breakthough in modern Physical AI comes from scaling up the Transformer architecture used by LLMs to an architecture known as VLAs (Vision-Language-Action) models in order to handle multi-modal inputs. LLMs would work by predicting the next word but VLAs models instead takes in a continuous stream of sensor data and outputs specific motor controls.
Mathematically, a traditional LLM defines a policy $\pi$ that predicts a discrete token $y_t$ based on a sequence of previous tokens: \(P(y_t) = \pi(y_{<t})\) However with a VLA model, it must compute a physical action $A_t$ at a specific time step, conditioned on both language instruction $L$ and continuous stream of visual observations perceived through sensor data $O_t$:
\[A_t = \pi(O_t, L)\]where $A_t$ is not a discrete word, it is a high-dimensional continuous vector representing joint angles, torque, velocities and end-effector coordinates on sensors such as actuators.
The Perception-Action Loop
The Perception-Action loop is a fundamental concept in robotics where Physical AI operated in a continuous, real-time feedback loop where it perceives the environent and takes actions based on those perceptions.
For example, a robot must contantly update its understanding of the world in real-time. If a a computer vision model running on a Humanoid robot detetcts an object held in its hands is slipping, the model must recalculate its trajectory in milliseconds. This requires running lots of neural networks on edge devices simulatenously. This means that the algorithmic efficiency and asymptotic complexity of the inference loop must be heavily optimised to achieve the necessary real-time control frequencies while maintaining the thermal and power limits of embedded hardware to a minimum.
Findings & Results
The Physical AI and Robotics industry is rapidly shifting away from single-purpose, hard-coded software toward general-purpose foundational models.
NVIDIA Project GR00T: GR00T (Generalist Robot 00 Technology) is a general-purpose foundation platform specifically designed to act as the brain for humanoid robots. It allows the NVIDiA hardware to learn from multimodal inputs such as text, video and human demonstrations. By utilising simulated workflows in Isaac sim alongside physical hardware, it enables robots to understand natural language and execute dexterous, coordinated movements natively in real-time.
Physical Intelligence $\pi_0$ (pi-zero): Physical Intelligence recently released $\pi_0$, a general-purpose robotic foundation model. Unlike previous generation VLA models that relied on discrete diffusion, $\pi_0$ combines a Vision-Language Model (VLM) with a continuous flow-matching architecture which enables precise and fluent manipulation skills which the model can then directly perform tasks based on a prompt or even fine-tunes on data to enable multiple complex tasks.
Google DeepMind’s Gemini Robotics: Google DeepMind Gemini Robotics recently introducedGemini Robotics 1.5 and Gemini Robotics-ER 1.6 models. These are advanced VLA and embodied reasoning models capable of long-context video understanding as well as multi-step planning. For example, a single model can control a diverse array of physical forms—from stationary dual-arm setups to full humanoids robotics, proving that massive scale and internet pre-training directly transfer to physical dexterity and spatial reasoning on physical robots.
My Takeaways:
After analysing the architectural shift towards Physical AI, a few points stood out to me:
- Intelligence requires interaction: True intelligence cannot exist purely on a data server. To understand the physical real world, an algorithm must be able to interact with it and experience the real-world consequences of force, gravity, friction…
- Data Starvation: Building the “brain” for Physical AI is only half the equation. We cannot easily scrape “real action data” from the internet in the same way we do text for LLMs. Training these brains requires an immense amount of high-fidelity, real-world physics data, which is currently the most critical bottleneck in the industry.
- Hardware-Software Bottleneck: While our software models are scaling great, the physical limitations of battery density, thermal dissipation on embedded systems and motor latency remain massive engineering hurdles.
Further Reading & References
- Generative Physical AI Overview: NVIDIA Glossary: Generative Physical AI
- Understanding Embodied Systems: IBM Think: What is Physical AI?
- NVIDIA Project GR00T: NVIDIA Developer: Project GR00T Foundation Model
- Google DeepMind Robotics: Google DeepMind: Gemini Robotics
- Physical Intelligence Platform: Physical Intelligence Home
- $\pi_0$ Technical Report: $\pi_0$: A Generalist Robotic Policy Technical Report (Physical Intelligence PDF)